Projects
Open Lecture
ChatGPT plugin that helps discover and access the relevant material in open course lectures.
Open Lecture is a ChatGPT plugin that allows you to search through university course materials to find timestamped lectures, notes, and course readings. ChatGPT is an amazing "tutor" but typically doesn't provide real sources or follow up material. This helps ChatGPT provide accurate responses and good targeted resources. Currently focused on MIT OpenCourseWare content.
Infrequently Asked Questions
Use LLM to generate a knowledge graph you can traverse to learn about a subject.
Melvins Mechanical Masterworks
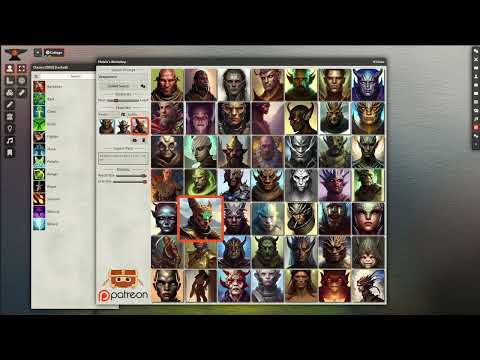
Generative Art for Tabletop Roleplaying
Demo

Actor Demo
Journal Demo

Build by Reid Sanders, Charles West, and Matthew Haentschke
Melvin's Mirror
Make yourself into a fantasy character



aiwhispers
Generative ASMR
Spatial Semantic Search with Voice Command
Wav2Vec2 live transcription + clip based similarity search in 3d scene in unreal engine

Fife
Program induction on a differentiable stack based VM
Experiments With Gans
All of these are quick experiments that don't devote nearly enough compute to make it look good.
Trypophobia
When someone put together a Trypophobia dataset on Kaggle. It looked like a perfect GAN dataset. The images were very textured. Can the GAN decode the essense of the phobia?
Trypophobia:

Text
When I was experimenting with training images on Gwern's Danbooru dataset I found a number of images included text. This isn't surprising as the dataset contains a fair amount of speech bubbles. It looked pretty good to me, but I can't read Japanese. So how far can it go? Transformers are being used to generate images. Can GANs be used to generate text?
Sentences:

Font
Can GAN's make a new font?
Font generation trained on 10k fonts:

Math
Can GAN's understand mathematics?
Self Driving Images
Generating Python Code with Transformers
In Karpathy's famous essay The Unreasonable Effectiveness of Recurrent Neural Networks his LSTM based network generates C code after training on the Linux source. This demonstration was sufficiently impressive that every now and then I'll revisit how well current language models can generate code. These are some rough experiments I ran a year ago, so are likely out of date already.
First I made a simple script that grabs a bunch of github python projects and extracts the python code.
Then I trained using the excellent Huggingface transformers project. This has a variety of pretrained transformers models. I tried GPT-2, Roberta, DistilBert, and XLNet.
I'll typically start with pretrained models because I don't have the compute to train from scratch in a reasonable timeframe. In this case the transfer learning was fairly good, but I would like to compare to a large trained from scratch network.
There are some complications. The bytepair encodings for existing models may not have some pairs we want for python. To try to fix this I ran the tokenizer.
python train_bytelevel_bpe.py --files 'data/*.txt'Then add the extra tokens using a simple script to find the missing tokens.
### find_vocab_diff.py ###
import argparse
import json
import os
parser = argparse.ArgumentParser()
parser.add_argument("first",
default=None,
metavar="path",
type=str,
help="Main vocab file. json")
parser.add_argument("second",
default=None,
metavar="path",
type=str,
help="Second vocab file. json")
parser.add_argument("--out",
default="./",
type=str,
help="Path to the output directory, where the extra vocab_file will be saved")
args = parser.parse_args()
with open(args.first) as f:
vocab1 = json.load(f)
with open(args.second) as f:
vocab2 = json.load(f)
new_vocab = [k for k,v in vocab2.items() if k not in vocab1]
i = len(vocab1)
vocab_dict = {}
for word in new_vocab:
print(i)
vocab_dict[word] = i
i+=1
print(vocab_dict)
with open(os.path.join(args.out,"added_tokens.json"),"w") as f:
json.dump(vocab_dict,f)Run with:
python find_vocab_diff.py models/PythonRoberta-base/config/vocab.json models/PythonRoberta-retokenized/vocab.json --out models/PythonRoberta-base/config/Training will look something like:
python run_language_modeling.py \
--output_dir=models/PythonRoberta-retrain \
--tokenizer_name=models/PythonRoberta-base/config/ \
--model_type=roberta \
--num_train_epochs 12 \
--save_steps 2500 \
--per_gpu_train_batch_size 6 \
--gradient_accumulation_steps 3 \
--per_gpu_eval_batch_size 6 \
--mlm \
--train_data_file data/train.txt \
--eval_data_file data/test.txt \
--overwrite_output_dir \
--dataset_name="python-roberta" \
--learning_rate 1e-4 \
--do_train \
--do_evalI ran into an error on some models:
/opt/conda/conda-bld/pytorch_1579022027550/work/aten/src/THC/THCTensorIndex.cu:361: void indexSelectLargeIndex(TensorInfo<T, IndexType>, TensorInfo<T, IndexType>, TensorInfo<long, IndexType>, int, int, IndexType, IndexType, long) [with T = float, IndexType = unsigned int, DstDim = 2, SrcDim = 2, IdxDim = -2, IndexIsMajor = true]: block: [239,0,0], thread: [95,0,0] Assertion `srcIndex < srcSelectDimSize` failed.I fixed it by changing the truncation length and block size to 256. I also checked that the pad token was correctly token_id=1 in train_byte_level_bpe.py.
...
class TextDataset(Dataset):
- def __init__(self, tokenizer: PreTrainedTokenizer, args, file_path: str, block_size=512):
+ def __init__(self, tokenizer: PreTrainedTokenizer, args, file_path: str, block_size=256):
assert os.path.isfile(file_path)
block_size = block_size - (tokenizer.max_len - tokenizer.max_len_single_sentence)
@@ -129,7 +129,7 @@ class TextDataset(Dataset):
class LineByLineTextDataset(Dataset):
- def __init__(self, tokenizer: PreTrainedTokenizer, args, file_path: str, block_size=512):
+ def __init__(self, tokenizer: PreTrainedTokenizer, args, file_path: str, block_size=256):
assert os.path.isfile(file_path)
# Here, we do not cache the features, operating under the assumption
# that we will soon use fast multithreaded tokenizers from the
...
- tokenizer.enable_truncation(max_length=512)
+ tokenizer.enable_truncation(max_length=256)
...
+++ b/train_bytelevel_bpe.py
@@ -38,8 +38,8 @@ tokenizer.train(
min_frequency=2,
show_progress=True,
special_tokens=[
- "<pad>",
"<s>",
+ "<pad>",This may not be an issue any more, or apply to your hardware.
Simple script to fill in a masked token for bidirectional examples.
from transformers import pipeline
from pprint import pp
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("input",
default="input-roberta.py",
type=str,
help="Path to the input file")
parser.add_argument("checkpoint",
default="checkpoint",
type=str,
help="The name of the output vocab files")
args = parser.parse_args()
fill_mask = pipeline(
"fill-mask-all",
model=args.checkpoint,
tokenizer=args.checkpoint,
)
with open(args.input) as f:
text = f.read()
result, stats = fill_mask(text)
with open("output.tet","w") as f:
stats_text = ''.join(stats)
print(stats_text)
f.write(stats_text)GPT-2 seems to get cleaner results, though Bert based models are bidirectional, making them a good fit for code transformation and autocomplete. Perhaps we'll have standardized formatters that will deterministically name things, solving one of the two hard problems in computer science. Cache invalidation will still be difficult though.
Some example gpt-2 generations after a short train (26000 steps):
$ python run_generation.py --model_type=gpt2 --model_name_or_path=outputs/output2/ --prompt "import os" --length 1000import os.system('clock.spiget', 0, 0, time_hours=1, gcp_conn_id='gcp_user')
with self.assertRaises(OSError):
os.system('sleep', 0, 0, time_hours=1, gcp_conn_id='gcp_user')
def test_no_spiget(self):
# Issue #15944: if no spiget exist on port 1, gcp_user will fail (EPILOGING the SPIGET %s
# and not be defined again)
super(OSError, self).test_no_spiget()
self.connection = self.make_connection(
self.name, self.connections_domain, self.spiget, 0, time_hours=3, gcp_conn_id='gcp_user')
self.assertTrue(os.stat(self.spiget, 0))
self.assertTrue(os.stat(self.connections_domain, 0))
def test_no_spiget_with_timeout(self):
# Issue #15944: if timeout option is set, gcp_user will fail with a non-staged socket
# connection.
self.connection = self.make_connection(
self.name, self.connections_domain, self.spiget, 0, timeout=4, gcp_conn_id='gcp_user')
self.assertTrue(os.stat(self.spiget, 0))
self.assertTrue(os.stat(self.connections_domain, 0))
def test_port_changed_before_change_over_timeout(self):
# Issue #15944: when changed, gcp_user will receive port 0.0.0.0 (for
#/home/user/spiget/works/monitor/?port=3&port_changed=1
# and allow 2 others to use the same port.)
self.connection = self.make_connection(
self.name, self.connections_domain, self.spiget, 0, port_changed=1, gcp_conn_id='gcp_user')
self.assertTrue(os.stat(self.spiget, 0))
self.assertTrue(os.stat(self.connections_domain, 0))
def test_works_username(self):
# Issue #15148: when no works match username, gcp_user will not be configured
self.connection = self.make_connection(
self.name, self.connections_domain, self.spiget, 0, username=gcp_user)
self.assertTrue(os.stat(self.spiget, 0))
self.assertTrue(os.stat(self.connections_domain, 0))
def test_ssh_interface(self):
# Issue #15147: when SSH command is not given, IP address defaults to '0.0.0.0'
# and has no SOCKS argument in it.
self.connection = self.make_connection(
self.name, self.connections_domain, self.spiget, 0, ssh_interface=False, id="default"
)
self.assertTrue(!python run_generation.py --model_type=gpt2 --model_name_or_path=outputs/output2/ --prompt "def find_match(" --length 1000def find_match(pathname):
# -- Newline characters help
try:
newline_line = dirname.encode('utf-8'))
except UnicodeError as ex:
raise AssertionError('Invalid option "%s" for separator. '
'pathname must be an ASCII string')
# This is the first time this checks a Windows prompt.
# On Windows, if you don't have any nested types in start_when, the
# *option* is not stored.
newline_line = str(str(str(ex))[1])[0]
if newline_line is None:
return None
self._add_option(newline_line)
def _from_option_vars(self):
# -- Default command for all command line arguments
return self.line_argument_group.args
def _get_number(self):
# -- Mark as variable name for how to call the argument.
return self.int_argument_group[::1]
def _get_control_title(self):
# -- Controls a char string for horizontal content
for command in self.command_list:
if command in getchar_string(command):
continue
if getchar_string(command):
command.title = command
return command
def _get_key(self):
if isinstance(self.state, dict):
return self.state == 'disabled'
if getchar_string(self.state) is None:
return 'from char string command line'+ self.name
return self
def __setitem__(self, key):
if key in self.x_list:
self.x_list.extend(key)
if self.current_x_buffer is not None:
if self.current_x_buffer.value == '':
self.x_list.pop(key)
else:
self.current_x_buffer.value = ''
self.current_x_buffer.pop(key)
def __call__(self, x):
if x.state == 'disabled' and self.state!= 'disabled' and not self.state =='set':
return self.name
else:
return 'from string command line'+ self.name
def _get_command(self):
if self.state == 'up' and getchar_string(self.state) == 'indent' and self.!Danbooru Utility
Danbooru Utility is a simple python script for working with gwern's Danbooru2018 dataset. It can explore the dataset, filter by tags, rating, and score, detect faces, and resize the images. I've been using it to make datasets for gan training.
Install
pip3 install danbooru-utilityMake sure you have downloaded Danbooru2018. It's ~3.3M annotated anime images, so downloading may take a long time.
Usage
First let's search for something fairly particular.
$ danbooru-utility \
--directory ~/datasets/danbooru-gwern/danbooru2018/ \
--rating "s" \
--required_tags "archer,toosaka_rin,hug" \
--max_examples 3 \
--img_size 256
Processed 3 files. Added 3 images. It took 14.39 secThis will find three images with the required tags, and resize them to 256x256. Note this took a long time since the filtering is just done in a loop. Let's check what this produced in out-images:



Now let's run the same command but with face detection:
$ danbooru-utility \
--directory ~/datasets/danbooru-gwern/danbooru2018/ \
--rating "s" \
--required_tags "archer,toosaka_rin,hug" \
--max_examples 3 \
--img_size 256 \
--faces
Processed 3 files. Added 1 images. It took 12.48 secThat produced:

So it cropped with the face in the upper center of the image.
Let's change the face_scale parameter. This controls how much of the image around the face is included in the crop.
$ danbooru-utility \
--directory ~/datasets/danbooru-gwern/danbooru2018/ \
--rating "s" \
--required_tags "archer,toosaka_rin,hug" \
--max_examples 3 \
--img_size 256 \
--faces \
--overwrite \
--face_scale 1.8
Processed 3 files. Added 1 images. It took 12.49 sec
A little tighter crop.
If you have already processed some images this utility will check and not reproduce them, unless you use --overwrite. So if you change image generation parameters you should use this flag. You can also specify a --link_dir to symlink to. So you can, for instance, resize a large number of images, and then create datasets for specific tags quickly.
So for GAN training I would use something like this to generate a training set:
$ danbooru-utility \
--directory ~/datasets/danbooru-gwern/danbooru2018/ \
--rating "s,q" \
--banned_tags "photo,comic" \
--max_examples 1000000000 \
--img_size 256 \
--faces
Processed 100 files. It took 10.36 sec
Processed 200 files. It took 20.06 sec
Processed 300 files. It took 39.16 sec
...Config
For details on parameters check help.
$ danbooru-utility -husage: danbooru-utility [-h] [-d DIRECTORY] [--metadata_dir METADATA_DIR]
[--save_dir SAVE_DIR] [--link_dir LINK_DIR]
[-r REQUIRED_TAGS] [-b BANNED_TAGS] [-a ATLEAST_TAGS]
[--ratings RATINGS] [--score_range SCORE_RANGE]
[-n ATLEAST_NUM] [--overwrite [OVERWRITE]]
[--preview [PREVIEW]] [--faces [FACES]]
[--face_scale FACE_SCALE]
[--max_examples MAX_EXAMPLES] [--img_size IMG_SIZE]
danbooru2018 utility script
optional arguments:
-h, --help show this help message and exit
-d DIRECTORY, --directory DIRECTORY
Danbooru dataset directory.
--metadata_dir METADATA_DIR
Metadata path below base directory. Will load all json
files here.
--save_dir SAVE_DIR Directory processed images are saved to.
--link_dir LINK_DIR Directory with already processed images. Used to
symlink to if the files exist.
-r REQUIRED_TAGS, --required_tags REQUIRED_TAGS
Tags required.
-b BANNED_TAGS, --banned_tags BANNED_TAGS
Tags disallowed.
-a ATLEAST_TAGS, --atleast_tags ATLEAST_TAGS
Requires some number of these tags.
--ratings RATINGS Only include images with these ratings. "s,q,e" are
the possible entries, and represent
"safe,questionable,explicit".
--score_range SCORE_RANGE
Only include images inside this score range.
-n ATLEAST_NUM, --atleast_num ATLEAST_NUM
Minimum number of atleast_tags required.
--overwrite [OVERWRITE]
Overwrite images in save directory.
--preview [PREVIEW] Preview images.
--faces [FACES] Detect faces and try to include them in top of image.
--face_scale FACE_SCALE
Height and width multiplier over size of face.
--max_examples MAX_EXAMPLES
Maximum number of files to load.
--img_size IMG_SIZE Size of side for resized images.Here's an example metadata entry in Danbooru2018:
{'approver_id': '0',
'created_at': '2016-10-26 09:32:42.38506 UTC',
'down_score': '0',
'favs': ['12082', '334419', '496852', '516035', '487870'],
'file_ext': 'jpg',
'file_size': '753165',
'has_children': False,
'id': '2524919',
'image_height': '874',
'image_width': '1181',
'is_banned': False,
'is_deleted': False,
'is_flagged': False,
'is_note_locked': False,
'is_pending': False,
'is_rating_locked': False,
'is_status_locked': False,
'last_commented_at': '1970-01-01 00:00:00 UTC',
'last_noted_at': '1970-01-01 00:00:00 UTC',
'md5': 'a9260780fbf5cfd661878f92a268124e',
'parent_id': '2524918',
'pixiv_id': '54348754',
'pools': [],
'rating': 's',
'score': '3',
'source': 'http://i3.pixiv.net/img-original/img/2015/12/31/13/31/23/54348754_p13.jpg',
'tags': [{'category': '0', 'id': '540830', 'name': '1boy'},
{'category': '0', 'id': '470575', 'name': '1girl'},
{'category': '1', 'id': '1332557', 'name': 'akira_(ubw)'},
{'category': '4', 'id': '396', 'name': 'archer'},
{'category': '0', 'id': '13200', 'name': 'black_hair'},
{'category': '0', 'id': '3389', 'name': 'blush'},
{'category': '0', 'id': '4563', 'name': 'bow'},
{'category': '0', 'id': '465619', 'name': 'closed_eyes'},
{'category': '0', 'id': '71730', 'name': 'dark_skin'},
{'category': '0', 'id': '610236', 'name': 'dark_skinned_male'},
{'category': '3', 'id': '5', 'name': 'fate/stay_night'},
{'category': '3', 'id': '662939', 'name': 'fate_(series)'},
{'category': '0', 'id': '374938', 'name': 'frown'},
{'category': '0', 'id': '374844', 'name': 'hair_bow'},
{'category': '0', 'id': '5126', 'name': 'hug'},
{'category': '0', 'id': '1815', 'name': 'smile'},
{'category': '0', 'id': '125238', 'name': 'sweatdrop'},
{'category': '4', 'id': '400140', 'name': 'toosaka_rin'},
{'category': '0', 'id': '652604', 'name': 'two_side_up'},
{'category': '0', 'id': '16581', 'name': 'white_hair'}],
'up_score': '3',
'updated_at': '2018-06-05 05:37:49.87865 UTC',
'uploader_id': '39276'}You can explore the metadata and find what tags are associated with each image using --preview.
Improvements
This could load the dataset into a relational database, allowing much more efficient and powerful querying.
The face detection has room for improvement. It has rare false positives, and a fair number of false negatives.
I'm happy to consider pull requests.
Acknowledgements
Thanks to gwern for the excellent danbooru dataset.
Thanks to nagadomi for the anime face detection model.